前言
本文主要介绍一些自然语言处理基础知识,涉及RNN、LSTM、CNN、transformer、bert等模型以及一些常见的问答、摘要、文本生成等典型应用场景。
早期语言表示的两种范式:概念驱动(WordNet)与符号驱动(独热编码)
早期自然语言处理(NLP)中存在两种基础且截然不同的词语表示方法:WordNet,它代表着强调人工语义结构的知识驱动/概念驱动范式;以及独热编码(One-Hot Encoding),它标志着将词视为离散符号的数据驱动范式开端。
一、知识驱动范式:基于概念的语义网络 (WordNet)
WordNet 是一个以“概念”为核心构建的英语词汇语义网络(lexical semantic database)。其核心思想源于认知科学:人类组织语言知识的基础是概念,而非孤立的词汇。
1.1 WordNet 的工作原理
WordNet 将语义相同或相近的一组词(即同义词)归入一个称为 同义词集(Synset) 的单元中。
- 唯一标识:一个词的具体含义可通过其所属的 Synset 唯一标识,格式为
{$词}.{$词性}.{$同义词集编号}。 - 示例:
- “I ate a red apple.” 中的水果“apple”表示为
apple.n.01。 - “I bought the new Apple.” 中的科技公司“Apple”表示为
Apple.n.02。
这种基于 Synset 的表示方法,本质上实现了词义消歧。
- “I ate a red apple.” 中的水果“apple”表示为
1.2 WordNet 的固有局限性
WordNet 虽语义清晰,但作为人工知识库存在固有缺陷:
| 局限性 | 描述 |
|---|---|
| 高度依赖人工构建 | 词义标注与网络扩展成本高、效率低,且带有主观性。 |
| 覆盖范围静态且有限 | 仅收录已有词形,难以涵盖新兴词汇、网络用语或领域特定术语(如 “ikun”)。 |
| 缺乏上下文感知能力 | 每个词义是静态固定的,无法根据具体语境动态调整;语义相似度基于人工结构,而非真实语言使用中的上下文统计。 |
二、数据驱动范式:基于符号的局部表示 (独热编码)
独热编码(One-Hot Encoding)思想将词语视为离散的符号(discrete symbols),而非连续的语义实体。这种方法被称为局部表示(Localist Representation)。它是现代深度学习语言模型的起点。
2.1 独热编码的工作原理
在独热编码体系中,每个词在词汇表中占据一个独立位置。它将每一个单词表示为一个高维稀疏向量,其中只有一个元素为 1(对应其在词汇表中的索引),其余均为 0。
- 词汇表:假设
['apple', 'banana', 'cherry', 'dog', 'cat'] - 编码示例:
apple=[1, 0, 0, 0, 0]banana=[0, 1, 0, 0, 0]
- 向量特性:向量维度等于词汇表大小(N),因此是 N 维极度稀疏的向量。
2.2 独热编码的根本缺陷
独热编码的“符号性”带来了结构上的简单性,但也导致了无法克服的缺陷:
| 缺陷 | 描述 |
|---|---|
| 维度灾难 (Curse of Dimensionality) | 向量长度与词汇量成正比。当词汇量达数十万时,计算成本和存储效率急剧恶化。 |
| 无法捕捉语义关系 | 任意两个不同词的向量彼此正交(点积为 0,余弦相似度为 0),即模型认为“hotel”和“motel”的相似度等同于“hotel”和“cat”的相似度。 |
现代统计NLP最成功的理念:基于上下文的分布表示
早期表示方法(WordNet 的人工概念和独热编码的孤立符号)的局限性,促使研究人员寻求一种数据驱动且能捕捉语义连续性的新方法。现代统计自然语言处理(NLP)最成功的理念基于一个核心假设:“一个单词的语义是由经常出现在它周围的单词给出的。”
因此,我们不再将词语视为孤立的符号,而是用一个词的上下文来构建它的语义表示,这种表示也叫分布式表示(Distributional Representation)。Word2Vec 是将分布式表示理念成功应用并推广的关键技术,它为后续的深度学习语言模型奠定了基础。
三、Word2Vec:分布式表示的开创性工作
3.1 Word2Vec 的核心训练流程
Word2Vec 通过无监督方式从大规模未标注文本语料中学习词的语义向量表示,即词嵌入(Word Embedding)。其训练流程主要包括以下三个步骤:
-
语料准备与预处理
模型以海量原始文本作为输入,无需人工标注。系统首先对文本进行分词、去噪等预处理,构建一个由所有唯一词组成的词汇表(vocabulary)。 -
初始化词向量
词汇表中的每个词被赋予一个可学习的低维稠密向量(通常维度为 100–300),作为模型参数的一部分。这些向量在训练开始时随机初始化,最终通过优化过程获得具有语义意义的嵌入表示。 -
建模上下文关系并优化概率分布
对于语料中任意位置 $t$ ,设中心词为 $w_t$ ,其上下文由窗口大小 $C$ 内的邻近词 ${w_{t+j} \mid -C \leq j \leq C, j \neq 0}$ 构成。Word2Vec 通过中心词与上下文词,计算条件概率,并使用 Softmax 函数进行归一化,从而建模词语间的共现统计规律。
3.2 两种概率模型架构与目标函数
Word2Vec 提出两种对称但方向相反的概率模型,均以最小化平均负对数似然为优化目标:
Skip-Gram(SG)模型
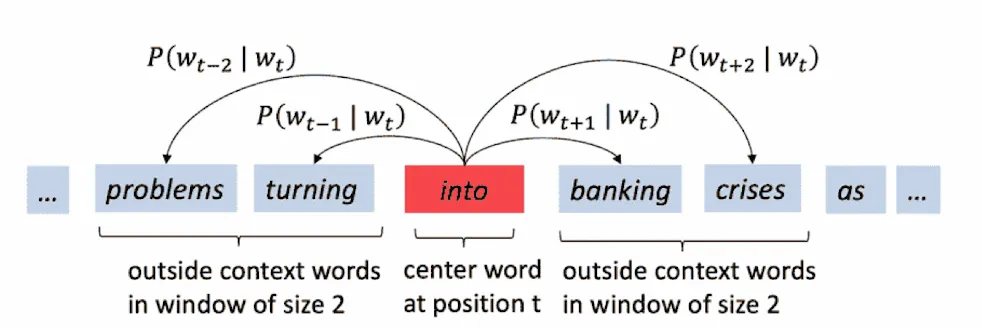
-
建模方向:以中心词预测上下文。
-
目标:给定中心词 $w_t$ ,最大化其在窗口内所有上下文词的联合条件概率。
-
似然函数:
$L(\theta) = \prod_{t=1}^{T} \prod_{\substack{-C \leq j \leq C \\ j \neq 0}} P(w_{t+j} \mid w_t; \theta)$ -
损失函数(平均负对数似然):
$J_{\text{SG}}(\theta) = -\frac{1}{T} \sum_{t=1}^{T} \sum_{\substack{-C \leq j \leq C \\ j \neq 0}} \log P(w_{t+j} \mid w_t; \theta)$
Continuous Bag-of-Words(CBOW)模型
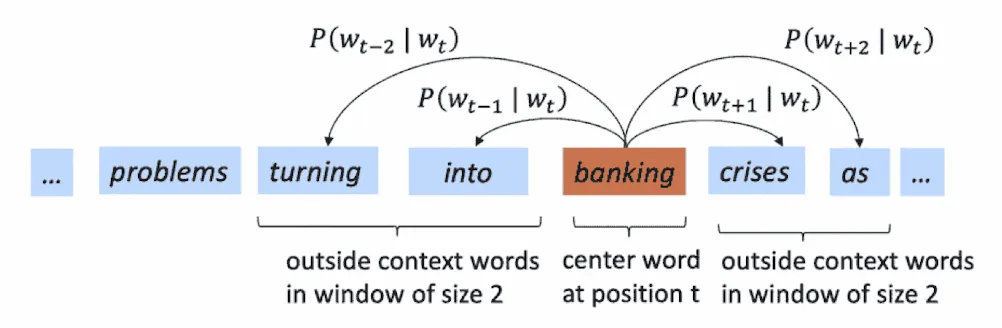
-
建模方向:以上下文预测中心词。
-
目标:利用窗口内所有上下文词(通常取其向量的平均或求和)预测中间的中心词 $w_t$ 。
-
似然函数:
$L(\theta) = \prod_{t=1}^{T} P\big(w_t \mid w_{t-C}, \dots, w_{t-1}, w_{t+1}, \dots, w_{t+C}; \theta\big)$ -
损失函数:
$J_{\text{CBOW}}(\theta) = -\frac{1}{T} \sum_{t=1}^{T} \log P\big(w_t \mid \text{Context}(w_t); \theta\big)$
两种模型在实践中各有优势——Skip-Gram 更适合小规模语料和稀有词建模,而 CBOW 训练更快、对高频词更稳定。