智能体通常被定义为:通过 Sensors 感知环境 Environment,并通过 Actuators 行动以达成特定任务的实体。为了理解智能体如何运作,我们首先要理解它的任务环境。在人工智能领域,常用 PEAS 模型来描述任务环境。
PEAS模型
- P (Performance):绩效/目标函数(要达成什么效果、如何衡量好坏)
- E (Environment):环境(智能体工作的外部世界、输入/约束、上下文)
- A (Actuators):执行器(智能体能采取的动作:输出什么、怎么影响环境)
- S (Sensors):传感器(智能体能接收的感知信息:读到哪些数据)
大语言模型驱动的智能体
大语言模型驱动的智能体,相比传统智能体,有诸多优势。

它的工作流程主要在三个方面取得了比较大的优化:
- 规划:智能体将高层次目标分解为逻辑子任务。
- 工具使用:智能体能主动调用工具来补全信息或响应动作。
- 动态修正:智能体能将用户的反馈视为新约束,从而做出相应调整。
智能体的运行机制
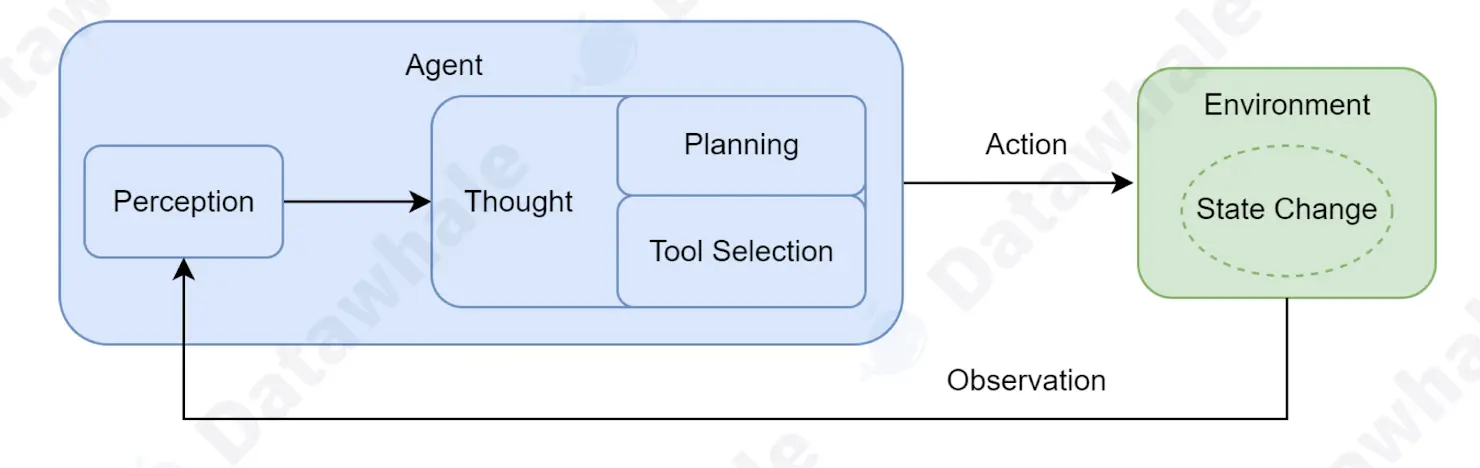
智能体在目标达成的过程中,是通过一个持续的循环与环境进行交互,这个过程也称为智能体循环(Agent Loop)。
- 感知(Perception)。智能体接收来自外部的信息。
- 思考(Thought)。智能体收到信息时候,进入决策阶段。该阶段可以细分为两个环节:
- 规划(Planning)。智能体基于对外部环境的观察和内部记忆更新对任务的理解,并制造整个行动计划。
- 工具选择(Tool Selection)。根据当前计划,智能体选择最合适的工具,并确定调用工具的参数。
- 行动(Action)。智能体通过执行器执行具体的行动。
- 目标达成。如果没有目标达成,则重复智能体循环;如果目标达成,则结束智能体循环。
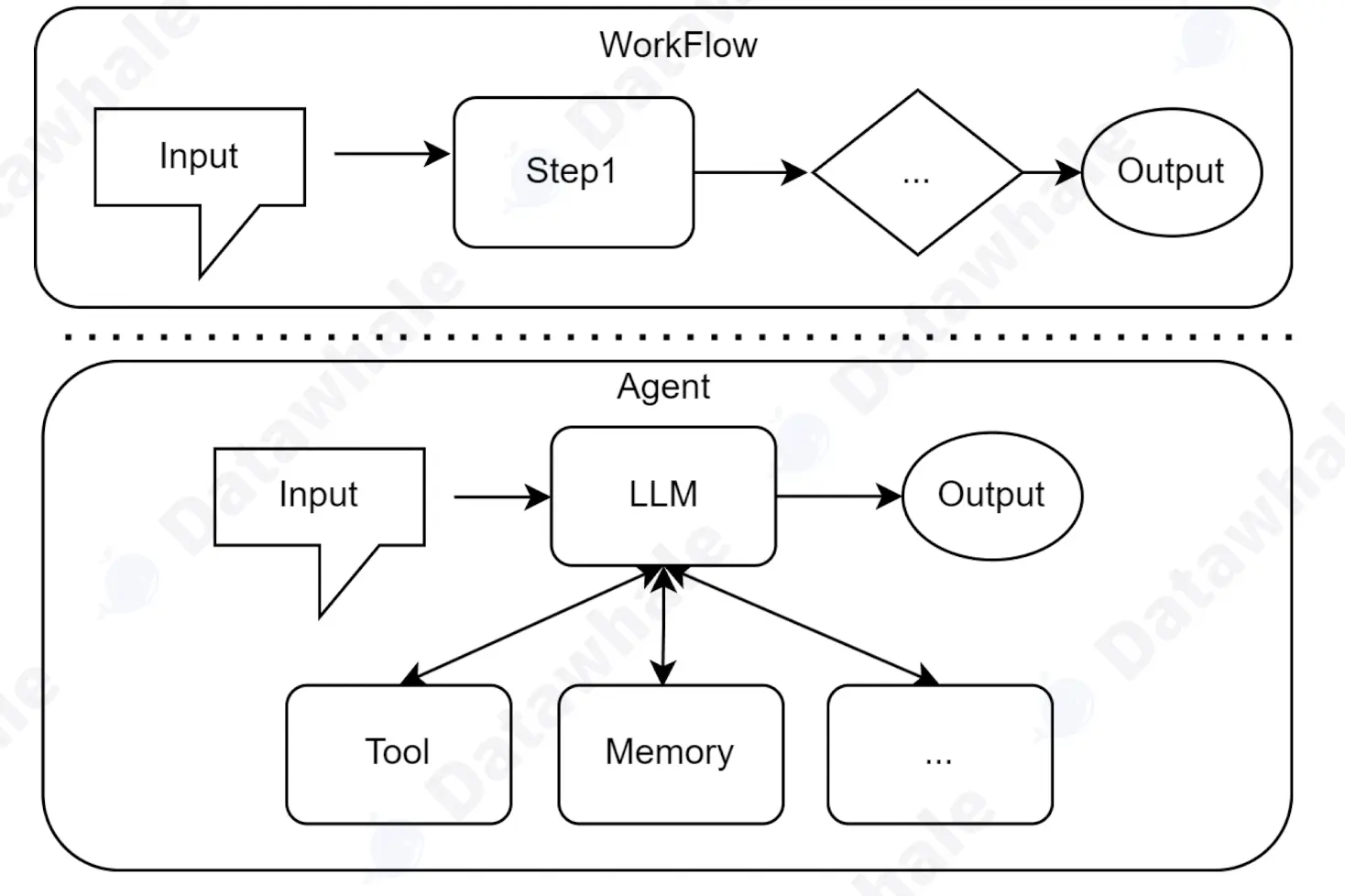
Workflow 和 Agent的差异
- Workflow(工作流)是对一系列任务和步骤进行预定义、结构化编排的自动化范式。它的本质是一个精确静态的流程图,严格规定了执行操作的顺序和条件。
- Agent(智能体)是一个具备感知、思考、行动、动态修正的系统。它可以按照多次智能体循环的方式达成最终目标。
课后题
判断以下四个 case 的主体系是否属于“智能体/智能体系统”(可多选并分析):
- case A:一台符合理结构的超级计算机,拥有高达每秒 2EFlop 的峰值算力
- case B:特斯拉自动驾驶系统在高速公路上行驶时,突然检测到前方有障碍物,需要在毫秒级做出刹车或变道决策
- case C:AlphaGo 在与人类棋手对弈时,需要评估当前局面并规划未来数十步的最优策略
- case D:ChatGPT 扮演的智能客服在处理用户投诉时,需要查询订单信息、分析问题原因、提供解决方案并安抚用户情绪
case A:不属于智能体
- 主要依据:超级计算机是算力硬件/通用高性能计算平台,本身并不具备“感知环境—决策—行动—目标达成”的闭环能力。
- 只有当它被具体算法系统驱动、并实现自主感知与决策/行动闭环时,才可能成为智能体的一部分;但题干只描述“算力很强的计算机”。
case B:属于智能体(Yes)
- 依据:
- 感知:前方障碍物
- 思考:选择刹车或变道
- 行动:控制车辆执行相应动作
- 目标:安全通过/避免碰撞
case C:属于智能体(Yes)
- 依据:
- 感知:棋局局面
- 思考:评估当前局面
- 行动:并选择下一步落子
- 目标:赢棋/最优策略
case D:属于智能体(Yes)
- 依据:
- 感知:理解用户投诉内容
- 思考:查询订单信息、分析问题原因
- 行动:给出解决方案并安抚情绪
- 目标:解决问题、提升用户满意度
假设你需要为一个“智能健身教练”设计任务环境。这个智能体能够:
- 通过可穿戴设备监测用户的心率、运动强度等生理数据
- 根据用户的健身目标(减脂/增肌/提升耐力)动态调整训练计划
- 在用户运动过程中提供实时语音指导和动作纠正
- 评估训练效果并给出饮食建议
请使用 PEAS 模型完整描述这个智能体的任务环境,并分析该环境具有哪些特性(如部分可观察、随机性、动态性等)。
P(Performance,绩效/目标)
- 达成用户健身目标:减脂/增肌/提升耐力的进展(体脂、肌肉、耐力指标随时间提升)
- 安全性:训练强度不过载、降低受伤风险(异常心率/疲劳时能及时降强度或提示停止)
- 训练效果:完成训练任务并能在合适强度区间产生有效刺激
- 可执行与体验:指导清晰、可跟做;饮食建议合理且能促进目标达成
- 效率:在安全前提下获得更好的训练收益(更少无效重复、减少失败/跳过)
E(Environment,环境)
- 用户的真实身体状态与约束:当前心肺水平、疲劳程度、既往伤病、动作能力等
- 训练场景与条件:室内/室外、器械可用性、空间限制、当天活动安排
- 数据与反馈环境:可穿戴设备/传感器的测量条件与误差、网络延迟(若有)
- 训练过程本身是“阶段性环境”:热身→训练→放松,状态随时间变化
- 用户行为的变化:用户可能未完全按指导执行(存在偏差)
A(Actuators,执行/作用方式)
- 输出训练计划与动态调整指令:推荐组数/次数/强度/节奏、调整训练内容
- 实时语音/文字/可视化指导:告诉用户“接下来做什么、怎么做”
- 动作纠正:提醒姿势错误、发出停止/减速/重做等指令
- 风险干预:检测到异常(如心率超出安全区间)时建议暂停、降强度或就医/咨询
- 饮食建议:给出摄入量与宏量营养建议、补剂/饮食时机等
S(Sensors,传感器/感知输入)
- 来自可穿戴设备的生理数据:心率、运动强度、(可能还有HRV/血氧等,视设备)
- 运动表现数据:训练时长、速度/配速/功率(如有)、步频/活动量、完成的动作次数
- (可选/扩展)动作数据:通过相机/IMU 识别动作姿态与偏差
- 用户目标与历史记录:减脂/增肌/耐力设定、历史训练日志与趋势
- 用户当前状态的间接信号:如主观疲劳/是否遵循指导(若系统采集)
为什么智能体/智能体系统会产生“幻觉”(生成看似合理但实际错误的信息)?
常见原因可概括为:智能体在循环中可能出现 感知误差(Perception)、思考误差(Thought)、行动误差(Action),而当缺少验证与反馈闭环时,错误会被持续放大,从而形成“幻觉”。
1)感知误差(Perception / 观测阶段)
- 上下文信息不全/观测不足(Partial Observability):关键事实不可获得(如售罄余量、价格、开放时间等),只能推断,导致输出偏离真实世界。
- 传感或工具观测带噪/不可靠:数据缺失、噪声、识别偏差,使得智能体“看到”的信息本身不准。
- 多轮对话中的误差累积:前一轮的错误观测/假设进入下一轮推理,形成“自我强化”的错因链条。
2)思考误差(Thought / 推理与规划阶段)
- 状态更新错误(belief update 错):智能体把旧信息当新信息,或更新记忆/约束时出错,导致后续决策基于错误前提。
- 约束/目标建模偏差:误解用户目标、预算或时间约束,使得生成的策略虽然“自洽”,但不满足真实要求。
- 证据不足下仍做强推断:当观测不完备时,未显式承认“不确定”,仍强行得出结论。
- 推理/规划的误差在循环中传播:某轮规划偏了,后续轮次不断“在偏差上优化”,最终更偏离正确答案。
3)行动误差(Action / 执行与输出阶段)
- 缺少真实世界的验证机制:未进行事实检索、工具查询或约束校验,模型只能靠语言先验补全,从而给出错误但合理的内容。
- 工具调用失败或数据过期:API 超时、返回空值或数据滞后;若缺少重试/降级/不可得提示兜底,仍可能继续生成。
- 行动后的反馈/观测闭环缺失:推荐或执行后没有再次感知核验(Observation),错误无法及时纠正并被带到下一轮。
如果最大循环次数没有限制,智能体可能会出现什么问题?
若把多轮 Thought-Action-Observation 循环无限放开,会出现:
-
无限循环/过度迭代
系统可能一直在找“下一步”,但没有真正收敛到可用结论。
-
成本与延迟大幅上升
每轮都要做推理/调用工具/生成文本,计算与 API 成本会暴涨。
-
误差越来越大(误差累积)
第一次推理可能已经偏了,后续循环会在错误基础上不断“修修补补”,最终更偏离事实。
-
策略漂移(目标被稀释)
原本目标可能是“生成一个满足条件的行程”,但循环太多会导致策略频繁变更,最后输出不稳定。
如何评估一个智能体的“智能程度”?仅使用准确率指标是否足够?
“智能”通常不仅是回答对不对,还包括:能否完成任务、能否适应环境、能否长期稳定、能否在不确定下做出正确决策。因此准确率通常不够。
- 任务目标达成率:最终是否真的满足目标(可执行、有效、安全)
- 感知质量:工具/传感输入是否可靠、缺失时是否能合理降级
- 思考质量:是否规划合理、是否能在约束下产生可行决策(回合数、工具次数可作代理指标)
- 行动可验证性(Grounding):输出是否基于真实工具/检索结果而非纯生成
- 动态修正能力:遇到反馈或冲突时,能否更新思考并继续走向目标
- 鲁棒性与安全性:异常情况下是否仍保持约束(预算、风险边界等)