整体架构
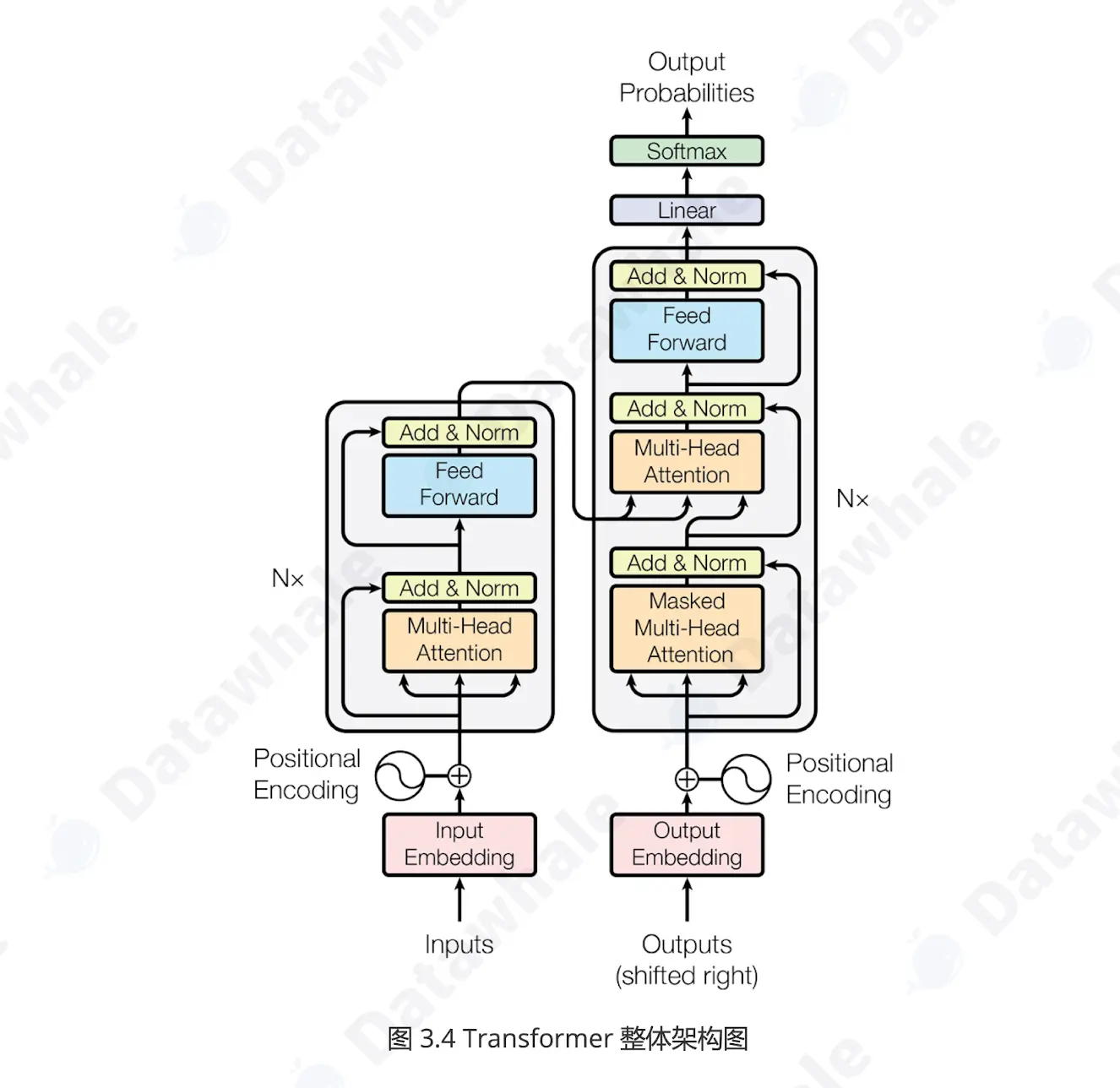
transformer整体架构由编码器和解码器构成。
- 编码器(Encoder):负责“理解”输入,它为每个Token生成一个包含上下文信息的向量表示。
- 解码器(Decoder):负责“生成”输出,它参考自己已经生成的前文,结合编码器的输出,生成下一个词。
代码实现
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
"""
位置编码模块
"""
def forward(self, x):
pass
class MultiHeadAttention(nn.Module):
"""
多头注意力模块
"""
def forward(self, query, key, value, mask):
pass
class PositionWiseFeedForward(nn.Module):
"""
位置前馈网络模块
"""
def forward(self, x):
pass
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention()
self.feed_forward = PositionWiseFeedForward()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 1.多头注意力
attn_output = self.self_attn(x, x, x, mask);
x = self.norm1(x + self.dropout(attn_output))
# 2.前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__int__()
self.self_attn = MultiHeadAttention()
self.cross_attn = MultiHeadAttention()
self.feed_forward = PositionWiseFeedForward()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# 1.掩码多头注意力
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 2.交叉注意力
cross_attn_output = self.cross_attn(x, encoder_output, encoder_output, src_mask)
x = self.norm2(x + self.dropout(cross_attn_output))
# 3.前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x;
核心概念
自注意力(Self-Attention)
自注意力(Self-Attention)允许模型在处理每一个Token时,都关注到其他Token,并给每个其他Token分配不同的权重。权重越高的Token,表示其与当前Token关联性越高。
自注意力通过为每个Token引入三个可学习的向量来实现:
- 查询(Query,Q):代表当前Token,它正在主动“查询”其他Token的信息。
- 键(Key,K):代表句子中被查询的Token的索引。
- 值(value,V):代表被查询的Token的信息。
这三个向量由原始的Token向量乘3个不同的可学习权重矩阵($W^Q, W^K, W^V$)得到,整个计算过程可以描述为:
- 计算QKV:对于句子中的每个词,由权重矩阵生成 $Q, K, V$向量。
- 计算相关性得分:将A与所有K向量点积运算(包括A自己),得到其他词对于A的相关性分数。
- 稳定化与归一化:将所有分数处以一个缩放因子 $\sqrt{d_k}$,防止梯度过小,然后用Softmax函数将Logits分数转换为概率分布。
- 加权求和:将上一步得到的每个权重乘每个词对应的V向量,并将所有结果相加,就得到了最终的A的向量表示。
用公式表示整个过程就是:
$\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V$
多头注意力(Multi-Head-Attention)
多头注意力可以让模型学到多组注意力权重,它将原始的QKV在维度上切分成h(头数)份,每一份独立计算注意力,再将h个输出向量拼接、线性整个,得到最终输出。
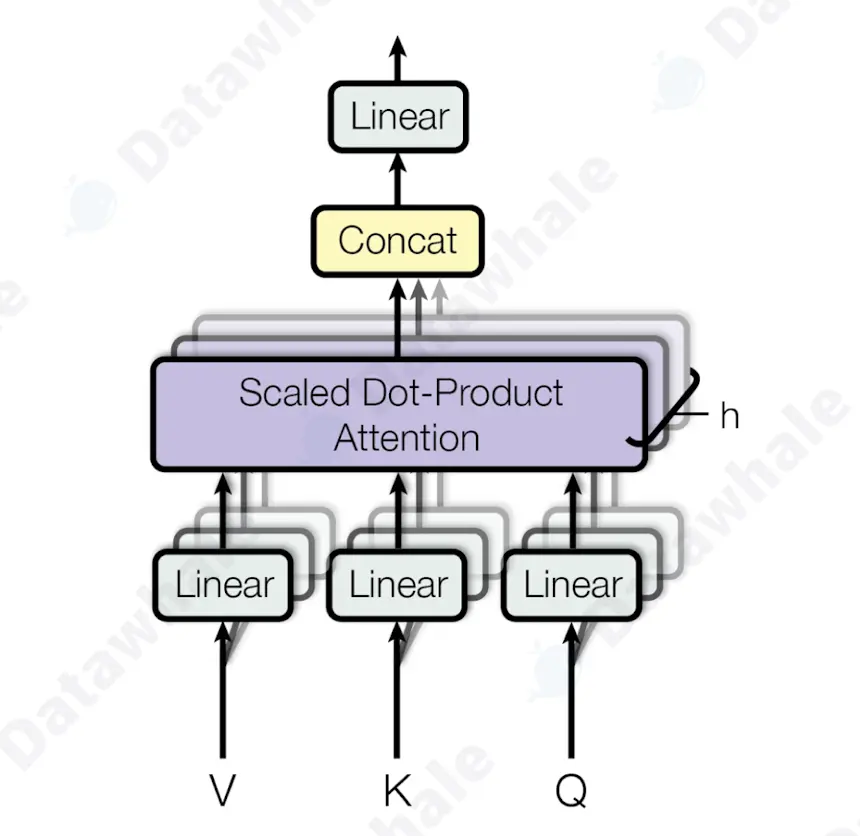
class MultiHeadAttention(nn.Module):
"""
多头注意力机制模块
"""
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_mdoel 需要被num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attenttion(self, Q, K, V, mask = None):
# 1. 计算注意力得分
attn_scores = torch.matmul(Q, K.transpose(-2, -1)/math.sqrt(self.d_k))
# 2. 应用掩码
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 3.计算注意力权重
attn_probs = torch.softmax(attn_scores, dim = -1)
# 4.加权求和
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
# 变化输入形状(batch_size, seq_length, d_model) 为 (batch_size, num_heads, seq_length, d_k)
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
batch_size, num_heads, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forwards(self, Q, K, V, mask = None):
# 1. 线性变换
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 2. 计算缩放点积注意力
attn_output = self.scaled_dot_product_attenttion(Q, K, V, mask)
# 3. 合并多头并线性变换
output = self.W_o(self.combine_heads(attn_output))
return output
前馈神经网络
在每个Encoder和Decoder层中,多头注意力子层之后是一个逐位置前馈网络(Position-wise Feed-Forward Network,FFN)。它的作用是从注意力层聚合的序列信息中提取更高阶的特征。逐位置,指的是独立处理序列中每一个Token向量,即一个长度为seq_len的序列,实际会被调用seq_len次。
这个网络由两个线性变换和一个ReLU激活函数组成。
$\text{FFN}(x) = \max\left(0, xW_1 + b_1\right)W_2 + b_2$
- x是注意力子层的输出。
- 通常第一个线性层的输出维度d_ff会大于x的维度,经过ReLU再通过第二个线性层映射回输入的维度。
- 先扩大再缩小的模式,被认为有助于模型学习更丰富的特征表示。
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout = 0.1):
super(PositionWiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
残差连接与层归一化
在每个Encoder和Decoder层中,每个子模块都被Add & Norm操作包裹,这个组合能保证Transformer稳定训练。
- 残差连接(Add):将子模块的输入x加到子模块的输出sublayer(x)上,这样可以解决梯度消失问题。反向传播时,梯度可以绕过子模块前向传播,保证了即使网络层数很深,模型也可以有效训练。
- 层归一化(Norm):对单个样本的特征归一化,让其均值为0,方差为1,解决了模型的内部协变量偏移问题,使输入分布稳定,进而加速收敛。
位置编码
Transformer计算两个Token之间的关系捕捉依赖,但它本身不包含任何词元顺序或位置的信息。为了解决这个问题,Transformer引入了位置编码(Postional Encoding)。位置编码的核心思想是为输入序列的每个Token向量,额外加一个代表其绝对位置和相对位置信息的位置向量,这个位置向量不是学习得到,而是固定的数学公式算出来的。通过这种方式处理,句子中不同位置的同一个Token,也会有不同的表示。
原论文中的位置编码生成方式:
$$
PE_{(pos,2i)} = \sin\left( \frac{pos}{10000^{2i/d_{\text{model}}}} \right) \newline
PE_{(pos,2i+1)} = \cos\left( \frac{pos}{10000^{2i/d_{\text{model}}}} \right)
$$
其中:
- $pos$ 是词元在序列中的位置(例如,$0$,$1$,$2$,…)
- $i$ 是位置向量中的维度索引(从 $0$ 到 $d_{\text{model}}/2$)
- $d_{\text{model}}$是词嵌入向量的维度
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""
位置编码初始化模块。
由于 Transformer 没有像 RNN 那样的顺序归纳偏置,需要显式地注入位置信息。
Args:
d_model (int): 模型的嵌入维度(即输入特征向量的长度)。
dropout (float): Dropout 的概率,用于防止过拟合。
max_len (int): 支持的最大序列长度。
"""
super().__init__()
# 初始化 Dropout 层,在 forward 中用于对加了位置编码的输入进行随机丢弃
self.dropout = nn.Dropout(p=dropout)
# 计算位置索引,形状为 (max_len, 1),方便后续与 div_term 进行广播计算
# torch.arange(max_len) 生成 [0, 1, 2, ..., max_len-1]
position = torch.arange(max_len).unsqueeze(1)
# 计算分母项,用于控制不同维度的正弦/余弦波的频率
# 公式为: 10000^(2i/d_model) 的倒数,即 exp(-log(10000) * 2i / d_model)
# 这里只计算偶数维度的项,形状为 (d_model // 2,)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
# 初始化位置编码矩阵,形状为 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
# 偶数维度使用 sin 函数,奇数维度使用 cos 函数
# 这种设计使得模型可以学习到相对位置关系(因为 sin/cos 之间存在线性转换关系)
pe[:, 0::2] = torch.sin(position * div_term) # 从第0列开始,每隔一列赋值
pe[:, 1::2] = torch.cos(position * div_term) # 从第1列开始,每隔一列赋值
# 将位置编码增加一个 batch 维度,变为 (1, max_len, d_model)
# 使用 register_buffer 将其注册为模型的缓冲区:
# 1. 它会随模型保存和加载 (state_dict)
# 2. 它会被移动到正确的设备 (CPU/GPU)
# 3. 它不是可学习参数,不会参与梯度更新
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播:将位置编码加到输入的词嵌入上。
Args:
x (torch.Tensor): 输入的词嵌入,形状通常为 (batch_size, seq_len, d_model)
Returns:
torch.Tensor: 加上位置编码并经过 Dropout 后的张量
"""
# 将位置编码加到输入张量上
# self.pe 的形状是 (1, max_len, d_model),x 的形状是 (batch_size, seq_len, d_model)
# 这里只截取与当前输入序列长度 (:x.size(1)) 相匹配的位置编码,利用广播机制相加
x = x + self.pe[:, :x.size(1)]
# 应用 Dropout 并返回
return self.dropout(x)
Decoder-Only
Transformer的设计哲学是“先理解,再生成”。编码器(Encoder)负责深入理解输入,形成一个包含全局上下文的记忆信息,解码器(Decoder)基于该记忆生成输出。但在GPT设计过程中,研发人员提出更简单的思路:语言的核心任务是生成。因此,他们抛弃了编码器,只保留了解码器部分。这种结构被称为Decoder-Only,这种工作模式被称为自回归(Autoregressive)。
整个工作过程可以概括为:
- 输入起始文本
- 基于上文,模型预测下一个可能的词
- 模型将自己预测的词追加到文本末尾,形成新上文。
- 重复2-3步骤,直到生成完整的句子停止。
为了避免模型偷看未来的答案,模型引入了掩码自注意力机制,将自注意力计算的注意力分数矩阵中,位于当前位置之后的token分数,替换为负无穷。这样在经过Softmax函数后,这些位置的概率变为0,从而避免了模型不依赖这些位置的信息。